HTML标签具有其语义和默认样式,例如a标签代表超链接(可点击跳转设置的url),p标签代表文本段落(默认换行显示)等,所以HTML标签在页面显示的效果就各有不同,有些会影响排版布局(分行,表格等),有些是媒体展示(图片,视频等)。
简数采集器的 “HTML标签过滤” 功能可指定只保留哪些HTML标签,根据HTML标签类型会出现两种情况:
1. 标签中有文本的默认会保留,把标签和排版格式去除,例如p标签,a标签等;
2. 标签是资源标签,即类似img标签,video标签等,会把这些媒体资源内容删除;
操作方法
1. 查看HTML标签过滤功能
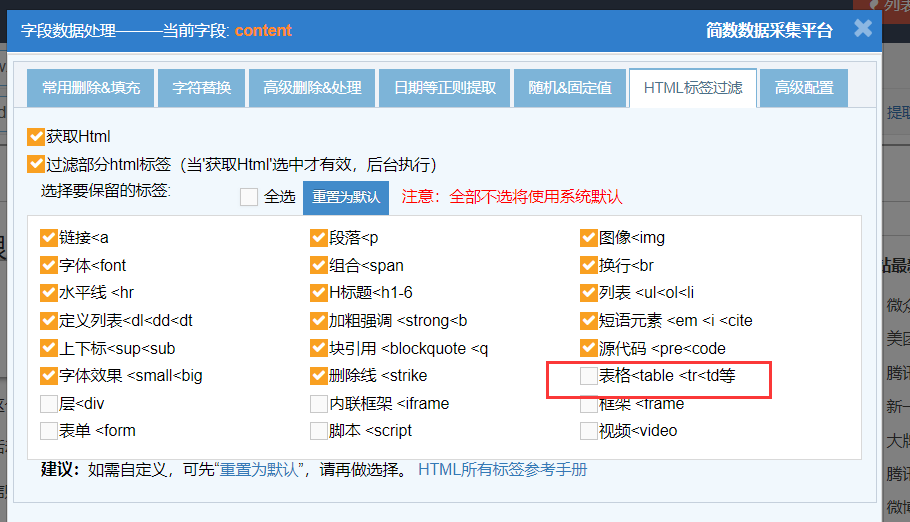
在简数采集器某个任务的详情提取器里,点击进入content字段的字段数据处理页面 --》点击切换到 “HTML标签过滤” 设置,勾上的是保留的标签。
简数采集器已默认过滤不需要不常用的标签,只保留常用的html标签,若无特殊需求用户一般不需要修改了。

2. 指定HTML标签保留或过滤
“HTML标签过滤” 功能生效的前提是,“获取Html” 和 “过滤部分html标签” 选项都勾上,然后下方的标签配置区域:勾选上的是保留,没勾选的是要过滤不保留。
2-1)例如采集的文章没排版时,可以尝试保留div标签解决。

2-2)例如不需要表格形式的显示,只需要其文本内容,请把table系列标签勾选掉后保存;