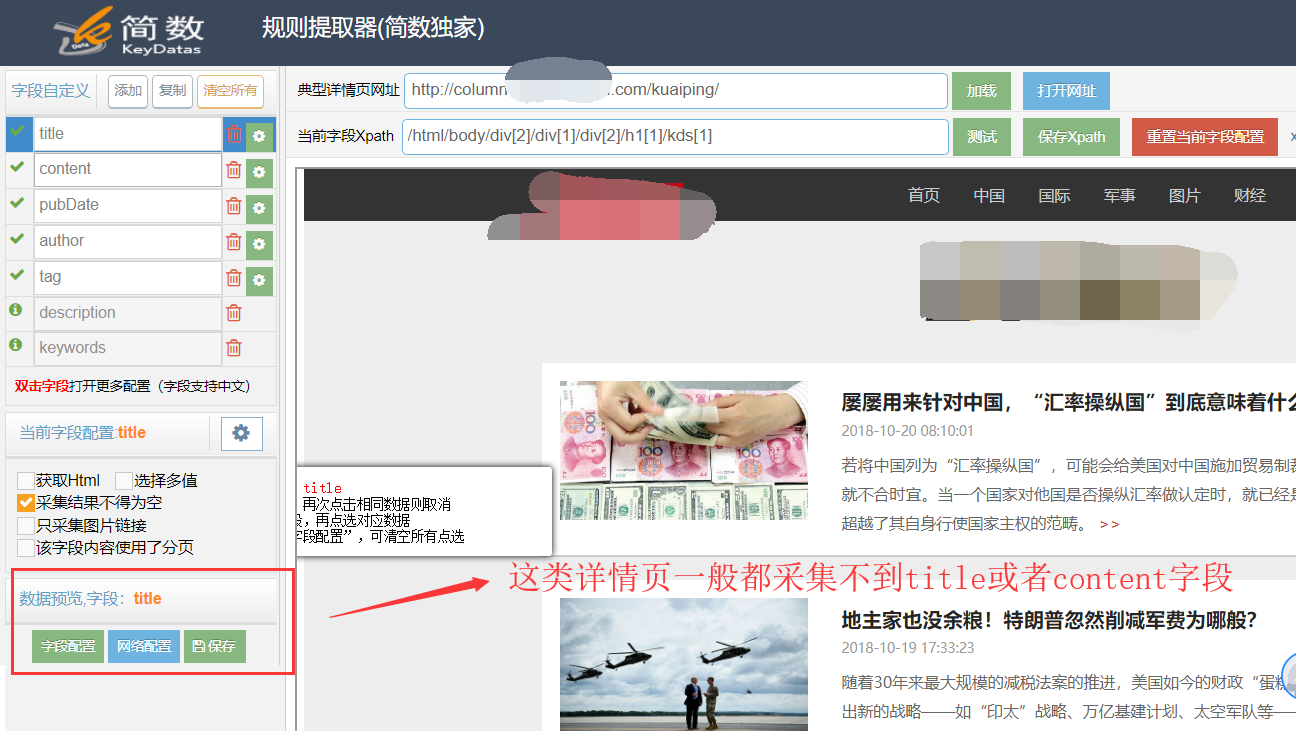
在列表页提取器选择要采集的网址链接时,中间夹杂着一些多余的页面链接,例如栏目链接、广告链接和标签链接等,要怎么解决?
可通过手写Xpath值来精确选择链接区域来解决。
但有个更简单的技巧,就是在详情页提取器使用 “采集结果不得为空” 功能,因为这些多余的页面结构排版和常规的文章页面都不一样,采集时就会过滤掉这些不符合采集规则的页面。
在简数采集器某个任务的详情页提取器,选择或输入正确的文章页面配置采集规则,title 字段和 content 字段处都勾上 “采集结果不得为空”即可。
1)采集文章页面时
title和content字段采集时都获取到对应的信息,系统就正常采集入库这条数据。
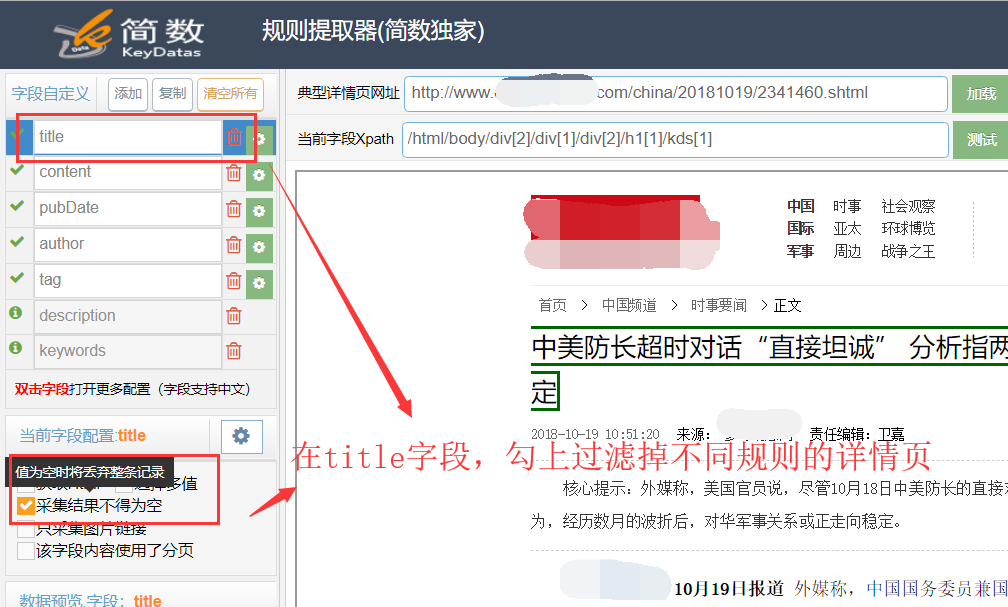
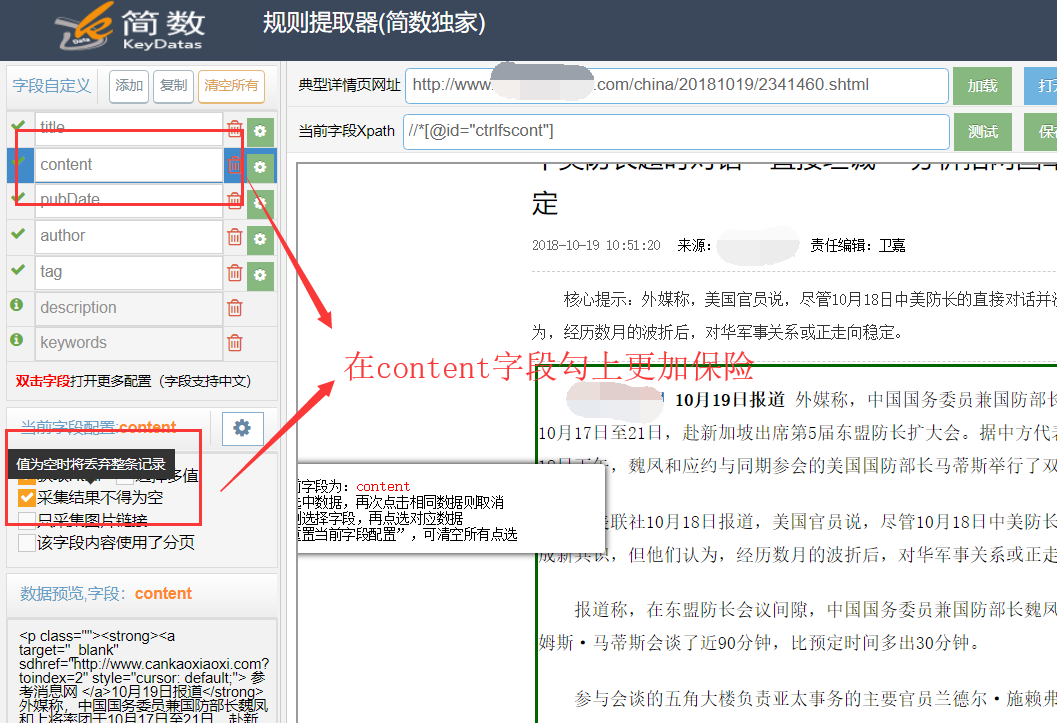
2)采集非文章页面时(例如广告,列表页面)
title或者content字段采集时没有获取到信息,系统就会过滤不入库这条数据。